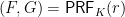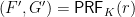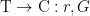We’ve had a fairly long-term issue at work with connectivity to one of our application servers. Every now and then you can’t login or connect and it has seemed fairly random. This finally annoyed myself and a customer enough that I had to look into it.
The connection is made to the server on port 1494 – Citrix ICA. Initially we suspected that the .ica file downloaded and opened by the Citrix Receiver software was incorrect or corrupt, but inspection and testing of this showed that it was OK. It really did look like the connection was just being randomly rejected.
It seemed that myself and a single customer were having far more frequent issues that other users. Of course it could just be my tolerance for whinging is lower than my colleagues.
Note that nearly all of the below was done on OS X – syntax of some of these commands differs under Linux and Windows. I have changed the host IP for security reasons.
telnet
Most applications that listen on a TCP port will respond to telnet, even if they don’t send anything back. Telnet is almost raw TCP – it has some control and escape sequences layered on top, but it is very simple at a protocol level.
ICA responds when connecting by sending back “ICA” every 5s:
andrew@andrews-mbp:/$ telnet 212.120.12.189 1494
Trying 212.120.12.189...
Connected to 212.120.12.189.
Escape character is '^]'.
ICAICA^]
telnet> quit
Connection closed.
But every now and then I was getting nothing back:
andrew@andrews-mbp:/$ telnet 212.120.12.189 1494
Trying 212.120.12.189...
telnet: connect to address 212.120.12.189: Operation timed out
telnet: Unable to connect to remote host
Oddly, whenever the Citrix Receiver failed to launch, I wasn’t always having problems with telnet, and vice versa. This is good – we’ve replicated the issue with a very simple utility using raw TCP rather than having to look into the intricate details of Citrix and whatever protocol it uses.
tcpdump
So let’s fire up tcpdump to see what happens when the connection is working. tcpdump is a command line packet analyser. It’s not as versatile or as easy to use as Wireshark, but it is quick and easy. You can use tcpdump to generate a .pcap file which can then be opened in Wireshark at a later date – this is good for when you are working on systems with no UI.
I filtered the tcpdump output to only show traffic where one of the two IPs was the server.
andrew@andrews-mbp:/$ sudo tcpdump -i en0 host 212.120.12.189
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on en0, link-type EN10MB (Ethernet), capture size 65535 bytes
23:16:40.027018 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [S], seq 2598665487, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027031986 ecr 0,sackOK,eol], length 0
23:16:40.080030 IP 212.120.12.189.ica > andrews-mbp.49425: Flags [S.], seq 3949093716, ack 2598665488, win 8192, options [mss 1400,nop,wscale 8,sackOK,TS val 188590479 ecr 1027031986], length 0
23:16:40.080173 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [.], ack 1, win 8241, options [nop,nop,TS val 1027032039 ecr 188590479], length 0
23:16:40.321664 IP 212.120.12.189.ica > andrews-mbp.49425: Flags [P.], seq 1:7, ack 1, win 260, options [nop,nop,TS val 188590504 ecr 1027032039], length 6
23:16:40.321739 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [.], ack 7, win 8240, options [nop,nop,TS val 1027032280 ecr 188590504], length 0
23:16:42.389928 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [F.], seq 1, ack 7, win 8240, options [nop,nop,TS val 1027034342 ecr 188590504], length 0
23:16:42.794413 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [F.], seq 1, ack 7, win 8240, options [nop,nop,TS val 1027034746 ecr 188590504], length 0
23:16:42.796361 IP 212.120.12.189.ica > andrews-mbp.49425: Flags [.], ack 2, win 260, options [nop,nop,TS val 188590739 ecr 1027034342], length 0
23:16:42.796430 IP andrews-mbp.49425 > 212.120.12.189.ica: Flags [.], ack 7, win 8240, options [nop,nop,TS val 1027034748 ecr 188590739], length 0
23:16:43.055123 IP 212.120.12.189.ica > andrews-mbp.49425: Flags [.], ack 2, win 260, options [nop,nop,TS val 188590777 ecr 1027034342], length 0
23:16:45.591455 IP 212.120.12.189.ica > andrews-mbp.49425: Flags [R.], seq 7, ack 2, win 0, length 0
This all looks fairly normal – my laptop is sending a SYN to the server, which responds with SYN-ACK, and then I respond with an ACK. You can see this in the “Flags” part of the capture. S, S., . (. means ACK in tcpdump). Everything then progresses normally until I close the connection.
However, when the connection fails:
23:23:31.617966 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027442033 ecr 0,sackOK,eol], length 0
23:23:32.812081 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027443220 ecr 0,sackOK,eol], length 0
23:23:33.822268 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027444226 ecr 0,sackOK,eol], length 0
23:23:34.830281 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027445232 ecr 0,sackOK,eol], length 0
23:23:35.837841 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027446234 ecr 0,sackOK,eol], length 0
23:23:36.846448 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027447234 ecr 0,sackOK,eol], length 0
23:23:38.863758 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 1027449238 ecr 0,sackOK,eol], length 0
23:23:42.913202 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,sackOK,eol], length 0
23:23:50.934613 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,sackOK,eol], length 0
23:24:07.023617 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,sackOK,eol], length 0
23:24:39.154686 IP andrews-mbp.49569 > 212.120.12.189.ica: Flags [S], seq 644234313, win 65535, options [mss 1460,sackOK,eol], length 0
I get nothing back at all – it’s just telnet trying the connection again and again by sending SYNs. I was expecting part of the connection to succeed, but this looked like the host just wasn’t responding at all. This might indicate a firewall or network issue rather than a problem with Citrix.
I used Wireshark on the server side to confirm that no traffic was getting through. I could see the successful connections progressing fine, but I could see nothing of the failing connections. I wanted to check both sides because there were a number of potential scenarios where a client could send a SYN and not get a SYN-ACK back:
- Client sends SYN, server never sees SYN.
- Client sends SYN, server sees SYN, server sends SYN-ACK back which is lost.
- Client send SYN, server sees SYN, choses not to respond.
It seemed that 1 was happening here.
So what was causing this? Sometimes it worked, sometimes it didn’t. Did it depend on what time I did it? Was there another variable involved?
mtr
Let’s check for outright packet loss. ping and traceroute are useful for diagnosing packet loss on a link, but it can be hard work working out which step is causing problems. Step in mtr, or my trace route. This provides a tabular, updating output which combines ping and traceroute with a lot of useful information.
My traceroute [v0.85]
andrews-mbp (0.0.0.0) Thu Dec 5 00:52:49 2013
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. router.asus.com 0.0% 36 1.8 4.6 1.2 104.0 17.0
2. 10.182.43.1 0.0% 36 10.1 41.3 8.1 291.2 68.1
3. haye-core-2a-ae6-642.network.virginmedia.net 0.0% 36 9.0 22.4 8.3 185.6 33.7
4. brnt-bb-1c-ae9-0.network.virginmedia.net 0.0% 36 13.5 13.8 8.9 80.2 11.6
5. brhm-bb-1c-et-700-0.network.virginmedia.net 0.0% 35 14.4 17.1 12.9 29.7 3.5
6. brhm-core-2a-ae0-0.network.virginmedia.net 0.0% 35 17.3 16.0 13.0 23.5 2.3
7. brhm-lam-2-tenge11.network.virginmedia.net 0.0% 35 14.5 15.3 12.5 21.1 2.0
8. m949-mp4.cvx2-b.bir.dial.ntli.net 0.0% 35 15.1 20.7 14.7 113.9 16.4
9. 212.120.12.189 0.0% 35 20.5 19.7 16.3 34.0 2.9
I let this run for a while and observed virtually no packet loss. It’s important to note that it is using ICMP pings – not TCP as Citrix uses. ICMP messages can be dealt with differently to TCP. mtr does support TCP pings but I can’t get it to work under OS X.
Python and telnetlib
So wrote a small Python program using the telnetlib module to periodically connect to the port using telnet and indicate when there were problems. The output was simple graphical representation so that I could spot any timing patterns.
import telnetlib
import time
import socket
WAITTIME = 5
RHOST = '212.120.12.189'
RPORT = 1494
STATFREQ = 16
StatCounter = 0
FailCounter = 0
while True:
time.sleep(WAITTIME)
if StatCounter != 0 and StatCounter % STATFREQ == 0:
print str(FailCounter) + ' / ' + str(StatCounter)
StatCounter += 1
Fail = False
try:
ica = telnetlib.Telnet(host=RHOST, port=RPORT, timeout=1)
except socket.timeout:
Fail = True
FailCounter += 1
if not Fail:
ica.close()
if Fail:
print '*',
else:
print '.',
So this prints a . for a successful connection and * for unsuccessful. After every 16 packets, the number of failures/total is printed.
. . . * . . * . . . . * . . * . 4 / 16
. . . * . * . . . . * . . * . . 8 / 32
. . * . . * . . . . * . * . . . 12 / 48
. . . * * . . . . . . * * . . . 16 / 64
. . . . * . . . . . . * * . . . 19 / 80
. . . * * . . . . . . * * . . . 23 / 96
. . . * * . . . . . . * . * . . 27 / 112
. * . . * . . * . . . * . . . . 31 / 128
* . . * . . . * . . * . . . * . 36 / 144
* . . . . . . * * . . . . . . * 40 / 160
. . . . . . * * . . . . . . * . 43 / 176
. . . . . * * . . . . . . * . . 46 / 192
. . . . * * . . . . . . * . . . 49 / 208
* . . . . . . * * . . . . . . * 53 / 224
. . . . . . . * * . . . . . . * 56 / 240
* . . . . . . * * . . . . . . * 60 / 256
What can we note?
- There is some vague pattern there, often repeating every 8 packets.
- The rate of failed to successful connections is nearly always 25%.
- Varying the WAITTIME (the time between connections) had some interesting effects. With short times, the patterns were regular. With longer times they seemed less regular.
- Using the laptop for other things would disrupt the pattern but packet loss stayed at 25%. Even with very little other traffic the loss was 25%.
What varies over time, following a pattern, but would show behaviour like this?
The source port.
Every TCP connection not only has a destination port, but a source port – typically in the range of 1025 to 65535. The source port is incremented for each connection made. So the first time I telnet it would be 43523, the next time 45324, then 45325 and so on. Other applications share the same series of source ports and increment it as they make connections.
When I run the test program with a short wait time, there is very little chance for other applications to increment the source port. When I run it with a longer wait time (30s or so), many other applications will increment the source port, causing the pattern to be inconsistent.
It really looked like certain source ports were failing to get through to the server.
netcat
I had to test this theory. You can’t control the source port with telnet, but you can with the excellent netcat (or nc, as the command is named). “-p” controls the source port:
andrew@andrews-mbp:/$ nc -p 1025 212.120.12.189 1494
ICA^C
andrew@andrews-mbp:/$ nc -p 1026 212.120.12.189 1494
^C
andrew@andrews-mbp:/$ nc -p 1027 212.120.12.189 1494
ICA^C
andrew@andrews-mbp:/$ nc -p 1025 212.120.12.189 1494
ICA^C
andrew@andrews-mbp:/$ nc -p 1026 212.120.12.189 1494
^C
andrew@andrews-mbp:/$ nc -p 1027 212.120.12.189 1494
ICA^C
As you can see – connections from 1025 and 1027 always succeed and 1026 always fail. I tested many other ports as well. We have our culprit!
Python and Scapy
Now, can we spot a pastern with the ports that are failing and those that are succeeding? Maybe. I needed something to craft some TCP/IP packets to test this out. I could use netcat and a bash script, but I’ve recently learnt about Scapy, a packet manipulation module for Python. It’s incredibly flexible but also very quick and easy. I learnt about it after reading the book Violent Python, which I would recommend if you want to quickly get using Python for some real world security testing.
The script needs to connect to the same destination port from a range of source ports and record the results. With Scapy, half an hour later, I have this (note, I did have some issues with Scapy and OS X that I will need to go over in another post):
import time
from scapy.all import *
RHOST = '212.120.12.189'
RPORT = 80
LPORT_LOW = 1025
LPORT_HIGH = LPORT_LOW + 128
for port in range(LPORT_LOW, LPORT_HIGH):
ip = IP(dst=RHOST)
# TCP sets SYN flag by default
tcp = TCP(dport=RPORT, sport=port)
# Build packet by layering TCP/IP
send_packet = ip/tcp
# Send packet and wait for a single response - aggressive timeout to speed up tests
recv_packet = sr1(send_packet, timeout=0.1, verbose=0)
# Red for failed tests, normal for success
if recv_packet is None:
colour_start = '�33[0;31m'
else:
colour_start = '�33[1;0m'
# Show source port in decimal, hex and binary to spot patterns
print colour_start + str(port) + ':' + format(port, '#04x') + ':' + format(port, '016b')
time.sleep(0.01)
This produced really helpful output. The failed packets are highlighted in the excerpt below:
1025:0x401:0000010000000001
1026:0x402:0000010000000010
1027:0x403:0000010000000011
1028:0x404:0000010000000100
1029:0x405:0000010000000101
1030:0x406:0000010000000110
1031:0x407:0000010000000111
1032:0x408:0000010000001000
1033:0x409:0000010000001001
1034:0x40a:0000010000001010
1035:0x40b:0000010000001011
1036:0x40c:0000010000001100
1037:0x40d:0000010000001101
1038:0x40e:0000010000001110
1039:0x40f:0000010000001111
1040:0x410:0000010000010000
1041:0x411:0000010000010001
1042:0x412:0000010000010010
1043:0x413:0000010000010011
1044:0x414:0000010000010100
1045:0x415:0000010000010101
1046:0x416:0000010000010110
1047:0x417:0000010000010111
1048:0x418:0000010000011000
At this point in the port range it appears that packets ending in 001 or 110 are failing.
1128:0x468:0000010001101000
1129:0x469:0000010001101001
1130:0x46a:0000010001101010
1131:0x46b:0000010001101011
1132:0x46c:0000010001101100
1133:0x46d:0000010001101101
1134:0x46e:0000010001101110
1135:0x46f:0000010001101111
1136:0x470:0000010001110000
1137:0x471:0000010001110001
1138:0x472:0000010001110010
1139:0x473:0000010001110011
1140:0x474:0000010001110100
1141:0x475:0000010001110101
1142:0x476:0000010001110110
1143:0x477:0000010001110111
1144:0x478:0000010001111000
1145:0x479:0000010001111001
1146:0x47a:0000010001111010
1147:0x47b:0000010001111011
1148:0x47c:0000010001111100
1149:0x47d:0000010001111101
1150:0x47e:0000010001111110
1151:0x47f:0000010001111111
Move further down the port range and packets ending 000 and 111 are failing.
In fact, at any given point it seems that the packets failing are either 000/111, 001/110, 010/101, 011/100 – complements of one another. Higher order bits seem to determine which pair is going to fail.
Curious!
What makes this even stranger is that changing the destination port (say, from 1494 to 80) gives you a different series of working/non-working source ports. 1025 works for 1494, but not 80. 1026 works for both. 1027 works only for 80.
All of my tests above have been done on my laptop over an internet connection. I wanted to test a local machine as well to narrow down the area the problem could be in – is it the perimeter firewall or the switch the server is connected to?
hping3
The local test machine is a Linux box which is missing Python but has hping3 on it. This is another useful tool that allows packets to be created with a great degree of flexibility. In many respects it feels like a combination of netcat and ping.
admin@NTPserver:~$ sudo hping3 10.168.40.189 -s 1025 -S -i u100000 -c 20 -p 1494
What does all this mean?
- First parameter is the IP to connect to.
- -s is the start of the source port range – hping3 will increment this by 1 each time unless -k is passed
- -S means set the SYN flag (similar to the Scapy test above)
- -i u100000 means wait 100000us between each ping
- -c 20 means send 20 pings
- -p 1494 is the offending port to connect to
And what do we get back?
--- 10.168.40.189 hping statistic ---
20 packets transmitted, 16 packets received, 20% packet loss
round-trip min/avg/max = 0.3/0.4/0.8 ms
The same sort of packet loss we were seeing before. Oddly, the source ports that work differ from this Linux box to my laptop.
Here’s where it gets even stranger. I then decided to try padding the SYN out with some data (which I think is valid for TCP, though I’ve never seen a real app do it and mtr’s man page says it isn’t). You use -d 1024 to append 1024 bytes of data. I first tried 1024 bytes and had 20% packet loss as before. They I tried 2048 bytes:
--- 10.168.40.189 hping statistic ---
20 packets transmitted, 20 packets received, 0% packet loss
round-trip min/avg/max = 0.5/0.6/0.9 ms
Wait? All the packets are now getting through?
Through a process of trial and error I found that anything with more than 1460 bytes of data was getting through fine. 1460 bytes of data + 20 bytes TCP header + 20 bytes IP header = 1500 bytes – this is the Ethernet MTU (Maximum Transmit Unit). Anything smaller than this can be sent in a single Ethernet frame, anthing bigger needs to be chopped up into multiple frames (although some Ethernet networks allow jumbo frames which are much bigger – this one doesn’t).
I then ran the hping3 test from my laptop and found that altering the data size had no impact on packet loss. I strongly suspect that this is because a router or firewall along the way is somehow modifying or reassembling the fragmented frames to inspect them, and then reassembling them in a different way.
At this point I installed the Broadcom Advanced Control Suite (BACS) on the server to see if I could see any further diagnostics or statistics to help. One thing quickly stood out – a counter labelled “Out of recv. buffer” was counting up almost in proportion to the number of SYN packets getting lost:

This doesn’t sound like a desirable thing. It turns out the driver is quite out of date – maybe I should have started here!
Conclusion
I’m still not sure what is going on here. The packets being rejected do seem to follow some kind of pattern, but it’s certainly not regular enough to blame it on the intentional behaviour of a firewall.
At this point we are going to try upgrading the drivers for the network card on the sever and see if this fixes the issue.
The point of all of the above is to show how quick and easy it can be to use easily available tools to investigate network issues.

 and a transponder
and a transponder 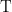 share a secret key
share a secret key  . A pseudo-random function family
. A pseudo-random function family  is keyed using key
is keyed using key  . The output from this PRF is split into two parts
. The output from this PRF is split into two parts  and
and  .
. .
.