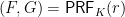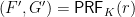When working with IoT and embedded systems, brute-force password guessing attacks are an effective tool to gain access. Over the years, I’ve learned some tips and tricks to make these attacks more effective.
What is brute forcing?
Very simply, it’s guessing passwords so that you can find a valid one and login to the device.
It’s often referred to as “password cracking”.
Online vs offline brute forcing
There are two forms of brute-force attack.
One is online. This means you are actively trying to login to the device using the web interface, telnet, SSH, or local console. This has disadvantages. It’s generally quite slow (less than 10 attempts per second, sometimes much slower) and account lockout is a challenge.
The other is offline. This is when you have the hash of a password and can guess passwords on an entirely separate machine. This has advantages. For many types of hash, hundreds of thousands of guesses can be performed each second. But, you need to have the hash in the first place.
(you can read a bit about hashes in an earlier post here)
If I have the device in front of me, and I can risk destroying it, I will generally obtain the hash and perform an offline attack. This isn’t always appropriate though – sometimes devices are too expensive or you cannot risk breaking it.
Sometimes the device has strong physical protections that make obtaining hashes difficult.
Often, an online attack can be setup and carried out in seconds – all you need is network access and a list of passwords. It’s often wise to try this first.
Do I need the password?
If your goal is to gain access to a device in front of you, make sure you have considered other paths.
Devices frequently have vulnerabilities allowing bypass of passwords. Command injection via web interfaces is still very common.
If you can modify the firmware, consider running an unauthenticated telnet shell. Or replace the password hash with one of your own, avoiding the existing password entirely.
What is the goal of getting the password?
With physical access to a device, time, and some skill, it is nearly always possible to login to a device without knowing any passwords.
So why do we want to find out the password?
Firstly, it’s very common to find hardcoded or default passwords on embedded systems. If you can find the password from one device, you can use it on many others. I call these BORE attacks – Break Once, Run Everywhere. The password has much higher value than just the device in front of you.
Secondly, you can perform a high-risk attack against a device on the bench, obtain a password, and then use that password in the real-world. This was what we did on an oil rig, where an attack was developed against a Siemens switch in the lab, and then the attack used on the rig itself.
Thirdly, it’s often possible to quickly and easily obtain a password hash from one device using something like the Cisco Password Recovery mode. You can quickly reset a Cisco switch on an non-critical, physically exposed switch, brute force the password, and then find that same password is in use on the core network.
How much effort are you willing to expend?
Obviously, the longer you spend guessing passwords, the more passwords you can guess.
Online brute force attacks are extremely rate-limited. The workload can be divided up by attacking multiple devices, but if you can obtain multiple devices, why not get the hashes from one of them and move to an offline brute force attack?
Offline brute force attacks cost in processor time. The more computing power and time spent, the more attempts you can make. You can literally throw processor time (and hence money) at the problem!
Depending on the value of the password, you may be willing to spend different amounts. A hardcoded root password for an IoT lightbulb behind NAT has a lot less value than the root password on a maritime satellite router with Internet exposed SSH!
Online attacks
There are three common network services which allow online brute force attacks to be carried out: Web interfaces, telnet and SSH.
A tool called hydra comes in very useful here. It handles these protocols and many more.
SSH is the easiest to deal with. Nearly all devices have a standard response, and the protocol feeds back if you have authenticated successfully or not.
Telnet is a bit awkward. The password prompt, and the feedback you get if you successfully login varies from device to device. Often you need to write scripts to do this properly. Always make sure you catch the success message properly – I once left a script running against a device for an entire weekend and it had found the password in less than 10 minutes.
Web interfaces can be easy sometimes, and incredibly challenging at others. The easiest are ones using HTTP Basic or Digest authentication – this is when you get the pop-up password Window in your browser. This can be easily attacked. Web forms take more effort – generally you need to intercept traffic and work out how the password is being sent. Some devices use JavaScript and other complex authentication flows that take significant effort to reverse engineer and replicate. An intercepting proxy such as Burp or Zap can be of use here.
If the device has account lockout, preventing you trying more than a few passwords, it is always worth checking that this persists through a device reset. It is very common for devices like DVRs to lockout for 15 minutes after 5 wrong guesses, but if you restart the device, the lockout has gone. A USB or WiFi-connected socket can be scripted to restart the device automatically.
Just be warned: a lot of ICS equipment responds badly to brute force attacks. Lockups and restarts are common, and I’ve even caused the relay output on one device to change state.
Cracking rigs
Calculating password hashes requires processor power. The first common password cracking tool, John the Ripper, made use of the main CPU in a machine.
It turns out that graphics cards are far more efficient at calculating most types of hash. Another password cracking tool, hashcat, became available, making use of multiple graphics cards. This hugely accelerated the rate at which passwords could be guessed, but required significant investment in hardware, and ongoing electricity and cooling costs.
Then cloud computing happened. It’s now possible to rent machines with graphics cards in them and perform password cracking in the cloud. You can spin up as many machines as required and use tools to split the workload amongst them. This can be very helpful when you do not know how often you need to perform password brute force attacks.
Picking your passwords
There are several common methods to generate lists of passwords to attack devices.
A dictionary attack takes a pre-generated list of words and tries them all. There are many readily available password dictionaries of varying quality, some contain millions of passwords. These dictionaries can be very effective against large sets of hashes, such as those from a website breach or Windows Active Directory.
Building your own dictionary based on the vendor and product can help. The tool CeWL can spider a website and return a list of words for use in password attacks.
A brute force or incremental attack tries all possible combinations. With these attacks, the character set used and the length of the password become important. The more characters tried and the longer the password, the larger the search space becomes and the longer an exhaustive search will take.
Most passwords consist of upper and lower case letters, numbers, and possibly symbols. The more of these that are used, the larger the search space.
- 26 lower case
- 26 upper case
- 10 numbers
- 10 common symbols
- 20 relatively common symbols
So, if the password contains lower/upper/number/common symbols, there are 72 possible characters.
If the password is 8 characters long, this results in 72^8 possible passwords. This is 7.22e14 – a very large number.
It’s at this point that we need to consider how quickly we can guess passwords. This is highly dependent on the hash algorithm used. For a typical high-end hashcat rig, the following are approximate rates.
| Algorithm | Guesses per second |
| MD5 | 200,000,000,000 |
| descrypt | 7,290,000,000 |
| md5crypt | 80,000,000 |
| bcrypt | 105,000 |
There is a huge variation here. This can dictate what kind of attack is viable. With our 72^8 attack above, the length of time for an exhaustive search for the above algorithms is as follows:
| Algorithm | Time |
| MD5 | 1 hour |
| descrypt | 1 day |
| md5crypt | 105 days |
| bcrypt | 218 years |
On average, the password will be found in half that time. 30 minutes vs over 100 years! It’s clear that brute-force is not a viable attack for bcrypt. For md5crypt, as long as you know the password is in that space, 105 days may be a reasonable expense depending on the value of that password.
This is also why it is key to understand the password complexity. descrypt only hashes the first 8 characters of the password. Combined with the speed at which we can guess, it makes exhaustive searches possible.
Let’s see what changing the character set does to the times if md5crypt is used.
| Character set | Options | Time |
| lower/upper | 52 | 7 days |
| lower/upper/number | 62 | 32 days |
| lower/upper/number/common symbol | 72 | 105 days |
| the kitchen sink | 92 | 2 years |
Again, there is huge variation. 7 days is likely viable, but it is a big risk assuming that no number of symbols were used. Equally, 2 years is a long time to spend to find a password and there is still a chance they used some quirky symbol and you never find the password.
Always keep in mind the language of the developers. It’s rare to find umlauts in US and UK passwords, but don’t assume that for a product developed in Germany.
And what about the password length changing? Again, with md5crypt and 72 characters.
| Password length | Time |
| 8 | 105 days |
| 10 | 1500 years |
| 12 | 8 million years |
| 14 | Yeah. |
It becomes obvious that if the password is longer, plain brute force attacks quickly become useless.
Hashcat also has other modes of operation that are more refined.
Mask attack mode takes a pattern and then applies a brute force attack within those limits. It’s very common to find that certain vendors, companies and users follow certain patterns, such as using iwhd7262, baid8621. Mask attack mode can be very helpful here.
This is also a good mode for things like passwords based on serial numbers and MAC addresses.
One of the most powerful modes is the rules mode. This takes a series of different rules and applies them to a list of passwords. This can be things like changing the case, appending numbers, swapping letter for numbers (i->1 a->4). There are complex sets of rules published, all of which can be very effective.
Open Source Intelligence
It is always worthwhile researching the vendor and their other products. The one you are looking at may not have a published password, but other products could, and they may follow a pattern.
In one instance, Samsung had a hardcoded root password across many of their cameras. Nearly all of their cameras used bcrypt, making an exhaustive search unlikely to succeed as it is so slow. However, one model of camera was using descrypt. An 8 character exhaustive search was carried out, yielding a complex (but short) password. This was found to be the same password on the device using bcrypt. With bcrypt, we would never have found the password.
Find it in other forms
Never assume that the password is only stored as a single hash on the device. It’s very common to find it hashed using different algorithms or stored in plaintext.
One device we looked at used Webmin for the web interface. This stored the passwords as descrypt, so an exhaustive 8 character search was started. This quickly gave up the passwords for all accounts.
The main Linux login used bcrypt though. Exactly the same accounts existed in Webmin as for the OS. Taking a stab in the dark, we assumed that the passwords were the same for both hashes, just truncated for the descrypt one. We knew the format and character set, so launched a hybrid attack using the first part which we already knew and brute force against the bit that we didn’t. We would never have found the passwords without the first 8 characters being known.
Passwords often get stored in plaintext. Common locations for this are WiFi hotspot configurations in hostapd.conf (the WiFi password is often the same as the OS login) and setup/factory reset scripts.
Conclusion
Hopefully the above tips and tricks have helped you understand password brute force attacks so that you can effectively use them against devices.





















 and a transponder
and a transponder 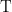 share a secret key
share a secret key  . A pseudo-random function family
. A pseudo-random function family  is keyed using key
is keyed using key  . The output from this PRF is split into two parts
. The output from this PRF is split into two parts  and
and  .
. .
.